Allgemeines
FAQ
Publikationen
Partner
|
Voriges Kapitel Nächstes Kapitel Inhaltsverzeichnis
Druck-Version
IV. Evolution und Leben: Zufall und Wahrscheinlichkeit
2.6. Die Entstehung des ersten Replikationssystems - Die Theorie vom Hyperzyklus
Der "Hyperzyklus" wurde von EIGEN als erstes evolutionsfähiges Replikationssystem postuliert. In dem einfachsten Hyperzyklus finden zwei RNA-Moleküle zusammen, die sich in gegenseitiger Wechselwirkung aus einer Substratlösung hervorbringen und "vermehren". Dabei koppeln sich entweder zwei oder mehrere selbstreproduzierende RNA-Stränge (Ribozyme) oder aber Ribozyme und Enzyme zu einem stabilen Autozyklus, der sich selbst unerhält und repliziert (vgl. Abbildung 1).
Abbildung 1:
Hier wird das schematische Prinzip eines sogenannten Hyperzyklus verdeutlicht, in dem zwei oder mehrere RNA- (RNS-) Sequenzen mit Enzymen (E) einen Zyklus bilden und sich gegenseitig erhalten. Beide dargestellten Sequenzen sind aufeinander angewiesen und können es sich nicht leisten, sich gegenseitig aus dem Rennen zu werfen.
EIGEN hatte das Modell vom Hyperzyclus ersonnen, weil die großen Fehlerraten bei der Vermehrung selbstreproduzierender Polynucleotide (Ribozyme) die "Information" ab einer bestimmten Sequenzlänge auseinanderdriften ließen. Nach jedem Replikationsschritt können nämlich Fehler (Mutationen) auftreten, so daß aus einer Ursequenz ein "Kometenschweif" ähnlicher Ribozyme entstehen kann. Diese bilden ein Mutantenensemble, die sogenannte "Quasispezies", die hinsichtlich Kopiergenauigkeit, Stabilität und Replikationsgeschwindigkeit miteinander in Konkurrenz stehen. Für Polynucleotide, die ausschließlich aus stabilen Guanin-Cytosin-Basenpaarungen bestehen, beträgt die experimentell bestimmte Fehlerquote etwa 1%, die Kette dürfte maximal 100 Nucleotide lang sein. Für Polynucleotide, die ausschließlich aus Adenin-Uridin-Basenpaaren bestehen, beträgt die Ablesefehlerquote bei der Replikation etwa das zehnfache, die Kettenlänge könnte also nur maximal 10 Glieder betragen.
Um nun eine stabile Reproduktion ohne "Informationsauflösung" über beliebig viele Generationen hinweg zu gewährleisten, ist es unmöglich, ein "Ur-Genom" auf einem einzelnen Molekül zu konzentrieren. Bilden sich in einer Quasispezies jedoch zwei oder mehrere Mutanten heraus, die ihre (eventuell durch Enzyme vermittelte) Reproduktion gegenseitig katalysieren und stabilisieren, entstehen kooperative Systeme, die sich über lange Zeiten stabil reproduzieren können und gegenüber allen anderen Konkurrenten im Mutantenensemble einen entscheidenden Vorteil besitzen. Als Bedingung muß gelten, daß jedes Ribozym aus 50-100 Kettengliedern besteht. Für das "Ur-Gen" muß man also einen Guanin-Cytosin-Reichtum von 50-100 % annehmen, da die RNA-Matrizen lediglich dann eine hinreichend kleine Fehlerquote besitzen.
Wie zu erwarten ist, wird von den Evolutionskritikern die Möglichkeit der hyperzyklischen Organisation der ersten Replikationssysteme infrage gestellt:
"Durch Experimente, welche EIGEN und Mitarbeiter mit dem von ihnen konzipierten Evolutionsreaktor durchgeführt haben, konnte jedoch die Entstehung eines Hyperzyklus nicht nachvollzogen werden. Vielmehr zeigen sie nur, daß vorgegebene gekoppelte Replikationssysteme unter entsprechenden Voraussetzungen (...) stabilisiert und optimiert werden können (...) Je besser ein solcher Hyperzyklus funktioniert, desto weniger geeignet ist er als Durchgangsstadium auf dem Weg zu einer primitiven Zelle."
(JUNKER und SCHERER, 1998, S. 145)
EIGEN und WINKLER-OSWATITSCH haben jedoch mathematisch zeigen können, daß die rezenten t-RNA-Moleküle einen Urzustand nahelegen, der genau einer Quasispezies-Verteilung aus sich individuell reproduzierenden Molekülen entsprach (EIGEN und WINKLER-OSWATITSCH 1981). Anhand der variablen Sequenzen konnte die hypothetische Ursequenz mathematisch rekonstruiert werden (KÄMPFE 1992, S. 201).
Interessant ist ferner, daß die rezenten t-RNAs genau die angesprochenen Eigenschaften (einen hohen Guanin-Cytosin-Anteil von ca. 80% sowie eine durchschnittliche Kettenlänge von 76 Nucleotiden) und damit dieselben Zahlenverhältnisse aufweisen, die die Theorie mathematisch erwarten läßt. Nimmt man hingegen eine geheimnisvolle "creatio ex nihilo" an, bleiben die Befunde unerklärt.
2.7. Die Entstehung des genetischen Codes
In der belebten Welt wird alle genetische "Information" auf dem DNA-Molekül gespeichert, das die gesamte "Bauanleitung" der Organismen enthält. Die DNA besteht abwechselnd aus einem Nucleotid- und einem Phosphatmolekül, die zu einer langen helical verdrillten Doppelschraube (Doppelhelix) verbunden sind (vgl. Abbildung 2). Jedes Nucleotid besteht wiederum aus einem Desoxyribosezuckermolekül, an dem chemisch eine von 4 verschiedenen Nucleotidbasen bindet, welche die "Buchstaben" des genetischen Codes verkörpern. Der gesamte DNA-Text besteht also aus 4 Buchstaben, nämlich den Nucleotidbasen Adenin (A), Guanin (G), Cytosin (C) und Thymin (T) bzw. Uridin (U) in der RNA anstelle des Thymins.
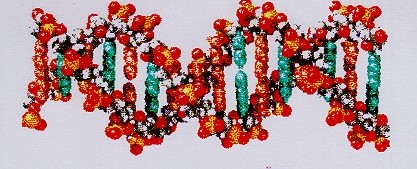
Abbildung 2:
Ausschnitt aus einem DNA-Molekül (Kalottenmodell). In der DNA sind zwei Fadenmoleküle spiralförmig umeinander gewickelt, die durch die Nucleotidbasen zusammengehalten werden. Die blauen bzw. organgefarbenen senkrechten Balken stellen hier die Nucleotidbasen dar; sie repräsentieren den genetischen Code. Die Spirale besteht aus einem Zucker (Desoxiribose), der chemisch mit Phosphorsäure verknüpft ist. Es existieren 4 verschiedene Nucleotidbasen: Adenin, Cytosin, Guanin und Thymin (bei der RNA anstelle Thymin: Uracil). Die Reihenfolge (Kombination) dieser Basen in dieser Doppelspirale ("Doppelhelix") charakterisiert das Genom des vorliegenden Organismus und repräsentiert dessen gesamte Erbanlagen und damit die Eigenschaften des Lebewesens.
Sollen nun in einer Zelle Teile der Bauanleitung (zur Produktion eines Proteins) abgelesen werden, wird die Doppelhelix an einer bestimmten Stelle aufgedrillt und eine Kopie in Form eines "Messengers" (m-RNA) angefertigt, der zum "Ablesen" (Translation) in den Zellkern geschleust wird. Die Buchstaben des Messengerstrangs werden dort der Reihe nach abgelesen, während jeweils 3 Buchstaben (ein bestimmtes Basentriplett) für eine bestimmte Aminosäure (ein "Wort") codieren. Mit dem Ablesen werden den "Wörtern" die für sie codierenden Aminosäuren zugewiesen, die der Reihe nach zu einem Protein verkettet werden, bis ein "Stop-Codon" erreicht ist, das die Synthese abbricht.
Interessant ist, daß alle Lebewesen einen recht einheitlichen ("universellen") Triplettcode besitzen, was für die gemeinsame Abstammung und die Evolution des Lebens spricht.
"Inzwischen hat sich aber herausgestellt, daß bei zahlreichen Organismen unterschiedliche Abweichungen vom sogenannten 'universellen Code' vorkommen (...) Damit ist der genetische Code zum Problemfall für die Evolutionstheorie geworden."
(JUNKER und SCHERER, 1998, S. 162)
Tatsächlich fand man vor einigen Jahren Abweichungen im genetischen Code, die vor allem die Mitochondrien der Säugetiere betreffen. So codiert in den Mitochondrien das Basentriplett UGA für die Aminosäure Tryptophan, während es im "universellen Code" die Aufgabe des Stopcodons übernimmt. Andererseits sind die Tripletts AGA und AGG in den Mitochondrien Stop-Signale, während sie im universellen Code für die Aminosäure Arginin stehen. Besonders auffällig ist hier, daß der mittleren Base G (Guanin) in der Frühzeit der Entstehung des genetischen Codes offenbar eine variable Bedeutung zukam.
Es erheben sich in diesem Zusammenhang vornehmlich drei Fragen: Warum codiert ein bestimmtes Basen-Triplett für eine bestimmte Aminosäure? Wie entwickelte sich der genetische Code, und lassen sich schließlich die Abweichungen im Code mit dem gängigen Entstehungsmodell erklären?
Die rezenten Organismen haben einen nichtüberlappenden, kommafreien Triplettcode, das heißt, jeweils 3 Nucleotidbasen auf der RNA kodieren für eine Aminosäure, die mit anderen zu einem Protein aneinandergereiht werden. Der Code ist heute eindeutig, das bedeutet, jedes Basentriplett codiert nur für eine einzige Aminosäure. Gleichzeitig ist er stark degeneriert, für die meisten Aminosäuren stehen mehrere Triplettcodes zur Verfügung. Schließlich fällt auf, daß die dritte Base stark variieren kann, ohne daß das Codon seine Bedeutung verliert; "informationsrelevant" sind also vorwiegend die ersten beiden Basen. Entsprechend der 4 Basen existieren 43 = 64 Kombinationsmöglichkeiten. Wenn nun durchschnittlich jeweils drei Codons für die 21 natürlich vorkommenden Aminosäuren codieren, bleiben drei Tripletts übrig, die als Stop-Codons beim Ablesen des genetischen Codes fungieren. Versucht man aus dem heutigen Zustand die Entstehungsgeschichte des genetischen Codes nachzuvollziehen, so ergibt sich folgendes Bild:
Die Variabilität der dritten Base im Codon legt nahe, daß sie zunächst in allen Fällen entbehrlich war. Es existierte also wahrscheinlich ein Dublett-Code, der für 42 = 16 Aminosäuren codieren konnte. Der Code wäre für die 13 in Simulationsexperimenten in bedeutenden Mengen gewonnenen Aminosäuren ausreichend gewesen, wobei bei 64 unterschiedlichen Tripletts jeder Aminosäure vier Codons zugeordnet gewesen wären. Interessanterweise besitzen heute noch sechs der just in Simulationsversuchen erhaltenen Aminosäuren 4 Codons; die Beobachtung kann mit dem Modell also ganz gut erklärt werden.
In einem noch früheren Stadium könnte evenutell nur die mittlere Codonbase über die zugehörige Aminosäure entschieden haben, die Aminosäuren also gruppenweise einer einzigen Base zugeordnet gewesen sein. Dieser primitive Zustand war mehrdeutig, jedes Triplett codierte also für mehrere Aminosäuren gleichzeitig. Tatsächlich codiert im heutigen Code U als mittlere Base für die hydrophoben Aminosäuren, C für die intermediären und G sowie A für die polaren und amidischen Aminosäuren (wie Arginin, Tryptophan usw.) sowie für den Stop-Befehl. Es scheint also, als ob der rezente Code aus einem mehrdeutigen protobiontischen Zustand hervorgegangen ist, in dem alle mittleren Basen gruppenweise für Aminosäuren codierten, wobei A und G für Stop-Codons und polare sowie amidische Basen gleichzeitig codierten.
Das Entstehungsmodell erklärt demnach, weshalb AGA, AGG sowie UGA einmal als Stop-Codons fungieren und einmal für Arginin und Tryptophan (als Stellvertreter der Gruppe der amidischen Aminosäuren) codieren. Der von JUNKER und SCHERER hervorgehobene Unterschied im Gencode ist somit kein "Problemfall" der Evolutionstheorie, sondern entspricht den Erwartungen des Entstehungsmodells vom genetischen Code. Es ist davon auszugehen, daß die Abweichungen vom Universalcode bereits zu einer Zeit auftraten, in der der Code noch mehrdeutig war, ein Umstand, der mit der Endosymbiontenhypothese der Zellbiologie konform geht. Ihr zufolge sind urtümliche Eubakterien mit Urprocaryonten-Zellen verschmolzen, während sich erstere zu Mitochondrien, den "Kraftwerken" der modernen Eucyte, umgebildet haben.
Interessant ist, daß nicht irgendwelche mittleren Basen (wie etwa Uracil oder Cytosin) für den Stopbefehl codieren, sondern sowohl im universellen wie auch im mitochondrischen Code die Basen Guanin oder Adenin. Ebenso interessant ist der Umstand, daß im Mitochondrialcode die zweite Guaninbase nicht für irgendeine Aminosäure codiert, sondern just für eine amidische, nämlich für das Tryptophan, genauso, wie es das Modell erwarten läßt. Die Beobachtungen verhalten sich mit anderen Worten völlig konsistent zur Evolutionstheorie, wenn man annimmt, daß sich in bestimmten Eubakterien und den Urkaryonten die Gencodes beim sukzessiven Übergang vom mehrdeutigen Einbasencode zum rezenten Triplettcode im Sinne des favorisierten Modells unterschiedlich spezialisierten, bevor sie eine Endosymbiose eingingen. Beide Modelle erfahren durch die Daten - ungeachtet offener mechanistischer Fragen - gleichermaßen eine Stütze.
Zweite, völlig neu bearbeitete Fassung, (c) 12.02.2002
Last update: 12.02.02








Voriges Kapitel Nächstes Kapitel Inhaltsverzeichnis (c) M. Neukamm, 30.08.2000
